

The environment
Machine Learning is ubiquitous today. Self-driving cars; self-shaving robots (just kidding, but I'm sure they can be constructed if the need arises); programs that teach themselves chess and become world-champion-class players overnight; Siri; google search engines; google translate - okay, I am going too far. But you know it: machine learning has become a player in almost every intellectual human occupation or complex task. The diffusion of deep neural networks, in particular, has been booming in the last few years. And what do particle physicists do?
Particle physicists have been caught a little bit pants down in this process. This is a *very* unfair qualification, but I drank two good IPAs tonight and I feel like using a few more hyperboles than what would be strictly needed to convey my message. Neural networks were pioneered in high-energy physics experiments already in the late _eighties_ , but they never really caught on there, partly because of the typical sceptical attitude of physicists, which I could summarize in the following two tenets:
1) if I did not code it myself, it probably does not work or is buggy; and it is anyway imperfect for sure.
2) even if I coded it myself, I start to doubt of its output if I do not understand any longer what is going on inside.
Yes, physicists are true bastards in this respect: they are among the most sceptical people on this planet. I use to say that this is all the more true when physics results are the topic, when the summit of scepticism is reached only when it is a result they did not participate in producing what is being discussed. So you get the point: we did realize quite early on that neural networks could be game changers, but we lacked the guts to fully rely on those tools for our oh-so-very-experts-only applications, like finding ways to select a tiny new physics signal amidst all sorts of uninteresting backgrounds, or regressing the energy of detected photons to improve the resolution of the reconstructed mass for Higgs bosons decayed to pairs of photons.
But now things have changed. LHC experiments (true standards setters in this field, I must say) have started to use deep neural networks (DNN) in some of their data analyses, with very promising improvements in performance. We in fact have problems that lend themselves quite well to machine learning tools like DNNs. I suspect that it will take a while for DNNs to dominate the proceedings, but eventually it's going to happen - we humans are simply not good enough at figuring out what goes on in multidimensional spaces such as those spanning the observed features of hugely complex particle collisions.
But what is a DNN?
For the benefit of those of you who do not know what I am talking about, and for some weird reason are still reading this article, let me explain what a DNN is. First let me explain what a NN is, and then it will be easy to add an adjective to it. A neural network (an "artificial" one, as natural neural networks are easily found inside the brain of all living creatures) is a computer program that emulates the structure of a natural NN.
The focus, though, is not to try and achieve intelligence by emulating a brain, and crossing reductionist fingers (the brain can be thought as the collection of its parts -that is reductionism- but many think there is more to it than meets a bisturi or a scanning electron microscope). The focus is rather to create systems that can learn structures in training data, so that when they are shown different data of similar kind they can very effectively interpret them and produce valuable output.
One simple example of the kind of problem a NN is keen to solve is the one of classification. You have usually two classes of elements, and for each element you know many features. An element could be a person, and then for each person you could know height, weight, eye colour, skin colour, and blood pressure, say. Would those data be enough to decide whether they carry an Indian or a Indonesian passport, on a statistical basis?
The way to solve this problem by machine learning is to create a set of labeled data - a set of Indian passport carriers and a set of Indonesian passport carriers. Then you input the relevant data of each element into a series of neurons, and simulate their behavior. A neuron is connected to many other neurons by a link, and they can either stay put or fire. If their input stimulates them to fire, they do, sending signals to other neurons. The process continues until you activate one end neuron -if the element was Indian, say- or fail to activate it -if the element was Indonesian. That is the output of the network of neurons, which allows the classification.
The network "learns" to classify Indian passport carriers one way and Indonesian passport carriers the other way by adjusting the characteristics of each neuron, such that these "fire" or stay silent in a way that produces the wanted output at the end. The relevant quantity that has to be minimized in the process is called "loss function", a number in some way proportional to how high was your failure rate -when the output neuron fired although the input data were those of an Indonesian citizen, e.g..
The adjustment process is performed by a trick called "back-propagation": once the network has seen the features of the two classes of labeled data, and produced an output (at the beginning it will be a random number, as the network does not have any prior knowledge of what distinguishes an Indian citizen from an Indonesian one among the used features), the data is "back-propagated" through the network, to see what would happen to the loss function if the activation function of this or that neuron were changed. By a process of successive approximation, the back-and-forthing of the data through the network produces a very small loss - the network has tuned itself to recognize the two classes.
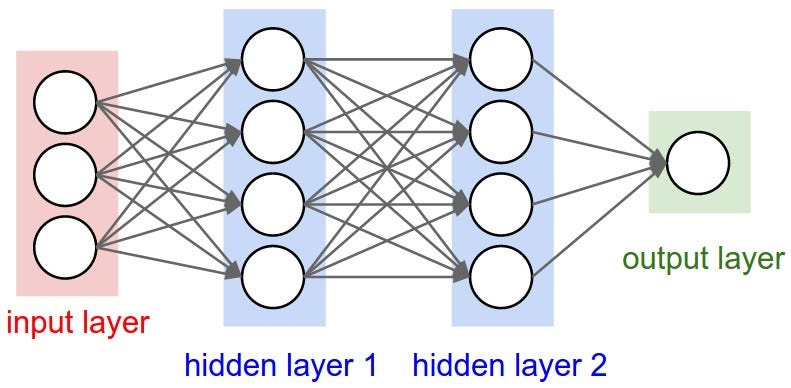
Above: the architecture of a very simple neural network. Data flows from left to right in normal operation, but can be back-propagated for loss optimization.
That is what a neural network is, or at least that is my shot at explaining how it works with the limited number of working neurons I have today. A "Deep" network is one that has many intermediate layers of neurons between the input and the output one - say three or more. That means that the features of each event are exploited multiple times in different ways by different batteries of neurons, that each send their output to the next layer in steps. Deep networks are harder to train, but they learn more complex features in the input data. These things can outperform any other existing method on the market, if tuned properly.
Where my idea comes from
Now that you know what a DNN is, I will tell you a story. Two and a half years ago I ranted, in a blog article, about the fact that those tools were being used in a rather dumb way by particle physics experiments seeking to classify signal and background events. What we did (and what we still do, in fact) was to train the network to achieve the best possible separation, the minimum loss, between the two classes of events we wanted to tell apart, using simulated data; and then applied the trained networks to real data. The resulting output was used to carry out some hypothesis test on the presence of the searched for signal in the data (hint: typically there is none - we are searching for physics beyond the standard model, but the standard model stubbornly remains all that there is in sight).
The problem was that although we tried to optimize the network training (and we bragged consistently about having done that in our scientific publications, the horror, the horror), the training itself was oblivious of the hypothesis tests that were carried out with the network output. And that latter phase included the accounting for all systematic uncertainties that could modify the result, e.g. by means of reshaping the features of the labeled data used for the training.
What resulted from this practice was a less-than-optimal final result of the all-important hypothesis test. In other words, we wanted to measure x (the signal rate in the data, say) with as small an uncertainty Δx as possible, but we were obtaining a significantly larger uncertainty once all systematic uncertainties were accounted for, and this could be thought to be sub-optimal. I knew it was.
I thus expressed the wish that somebody would come up with a "Meta-MVA", where MVA stands for "multivariate algorithm", a DNN in our case. I reasoned that we ought to be able to let the loss of our neural network know about -pardon: to encode in the NN loss- the effect of those systematic uncertainties. But I did not know how this could be done in practice.
Enter Pablo. Pablo de Castro Manzano is a Ph.D. student I hired with European Committee money coming from the "Horizon2020" Innovative Training Network program I called "AMVA4NewPhysics" (advanced MVA for new physics searches at the LHC). Pablo is highly knowledgeable about machine learning (partly due to the fact that we trained him well!), and he is a wizard when coding things in advanced software languages. He at some point decided to take on my virtual challenge, and he produced, with very little input from me, an amazing algorithm that does precisely what I had asked for: classification that knows about what you want to do with the output, so that the DNN optimization produces the best possible result on x, i.e. the smallest possible uncertainty Δx once all systematic effects have been accounted for.
We wrote a first version of an article on this topic, and it's in the arxiv (the algorithm has a catchy name: INFERNO, from "inference-aware neural optimization"). The one out there is a preliminary version and the results displayed there do not look that impressive, but now we are finalizing a second version that really shows just how huge can the improvement be in the final goal if you do a true optimization in the problem. So if you are seriously interested in the topic you should wait for this second version, or come to our "Statistics for Physicists" workshop in Padova next week, where Pablo will present a poster on the matter.
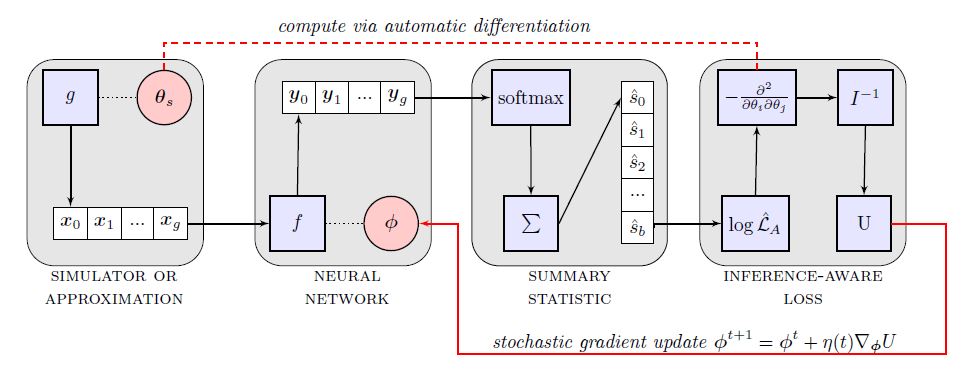
Above: a block-diagram describing the structure of the INFERNO algorithm. Yes, it is complicated. No, I am not going to explain it here - you will have to read our article if you want to make sense of it.
Meta-Design of a Particle Detector
Anyway. This above was just the introduction. In analogy with the story above, I am now thinking at a grander challenge. It so happens that experimental physicists these days are thinking at what the next big particle collider is going to be. These things take 20 years to be built, so we have to do it now if we want to keep the research field alive. One important thing in such an endeavour is the detector that you build around the point where you bring the projectiles (protons or electrons) to collide.
Through decades of big and small improvements based on accurate and painstaking studies, we have amassed a lot of know-how on effective ways to build a suitable particle detector that can be redundant and precise enough for the purposes we have in mind. So although we want to put in our new detector as much new technology as we can, that new technology more or less already exists on the market today: it is very hard to speculate on hardware that we have not invented yet. (We do speculate on the availability of technology in the future sometimes, but we have to have a rather clear idea of how we will get there.)
When one designs a particle detector, what one has in mind is the challenge of making sense of the electronic output of the detector components. We have perfected the software reconstruction of particle trajectories and momenta through years and years of work, with more and more refined pattern recognition tools and cutting edge methods. But this does not use machine learning in a systematic way: there are many studies of how to use machine learning for these tasks, but a coherent approach is still unachieved.
But DNNs do exist today. And we are damn sure they are exponentially growing in performance, complexity, adaptability. These things may well be the seeds of a paradigm shift, an artificial intelligence revolution, in the matter of a few decades. So my thought is that while we can be pretty good at designing particle detectors whose output we can interpret and make sense of with the algorithms we have today, it is not granted that in 20 years what we design today will be the best object in terms of its exploitation by very complex, advanced DNN algorithms.
In other words: if we keep designing detectors that can produce an output we can as humans make sense of in the best and robust way, we are not optimizing their design for the tools that will take our place in decyphering the electronic signals in 20 years from now. If those tools are as advanced as the most advanced DNNs that exist today, the answer is already a resounding "nope" -we are not making the right choices already. And this may become even more critical if we consider that the machine learning tools that will be around in 20 years are going to be at a new level of awesomeness.
How can we improve the picture?
It is extremely hard. But there are ideas I could throw in, just for the fun of arguing.
One thing to note is the fact that until now we always constructed collider detectors using the paradigm "Measure first, destroy later": we first measure the path of charged particles in what is called a "tracker"- a device with very thin material (gas or thin layers of silicon, e.g.) where the particles ionize the medium but do not significantly degrade their properties and momenta; and only later on do we allow those particles, along with the neutral ones we could not track anyway, to interact with dense materials in "calorimeters", where we content ourselves with measuring the energy of the incident bodies, and only roughly measure their directions.
Can we change that paradigm, for the benefit of a smarter reconstruction of the properties of particles produced in the collisions? We can, sure. For calorimeters nowadays can do both things at once: track and measure energy. Imaging of particle showers, performed with machine learning tools, is a much-researched and advanced topic today, and DNNs are of course big players there. In fact, it has been proven that DNN tools can use calorimeter signals also to identify muons of very high momentum, as the muons exhibit a subtle property called "relativistic radiation rise" at high momentum, something that nobody thought would be exploitable for particle identification, until DNN were put to the task.
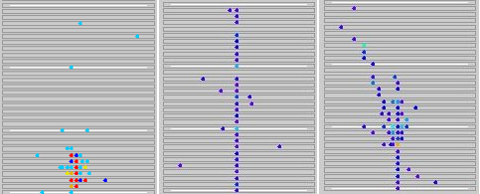
Above: signal reconstruction in the simulation of an imaging calorimeter designed for a new linear collider, ILC. Different particles provide different patterns of the reconstructed energy deposits: left to right, what to me seems the result of a photon or electron signal, a muon signal, and a single hadron signal. Particles come from the bottom. (I could be wrong, but it is nice to guess!)
Hence my wish: can we imagine a process by means of which we allow DNNs to guide us to produce the most fruitful design of a collider detector, allowing us to escape from misconceptions and ad-hockery which served us well until we had to reconstruct collisions with dumb algorithms? I can think of ways to embark in a systematic study of this kind. It would be very difficult, but I bet it would guarantee that we would be truly "optimizing" the performance of whatever detector we end up designing at the end of the day.
Just to give an example of how we could perform this task: break it in pieces. Study a single slice of whatever detector arrangement you want to start with, define your DNN loss to be a combination of classification errors and resolution degradations, and train the algorithm with lots of different kinds of data, allowing the DNN to change the detector geometry and layout, expressed as parameters in the architecture. Then iterate with different parts of the proposed initial scheme, and evolve toward solutions which exploit the way DNNs can interpret the resulting data output. Simple, ain't it? Ok, it is not simple at all!, but we have a few years to play with this, and it looks quite cool!
---
Tommaso Dorigo is an experimental particle physicist who works for the INFN at the University of Padova, and collaborates with the CMS experiment at the CERN LHC. He coordinates the European network AMVA4NewPhysics as well as research in accelerator-based physics for INFN-Padova, and is an editor of the journal Reviews in Physics. In 2016 Dorigo published the book “Anomaly! Collider physics and the quest for new phenomena at Fermilab”. You can get a copy of the book on Amazon.




Comments