I reported here a few days ago about a very nice challenge issued by the ATLAS experiment: find Higgs boson decays to tau lepton pairs in a sample containing signal as well as background events, using a training sample with correct signal and background labels per each event.
The challenge consists of solving a typical classification problem in a highly multidimensional space (30 dimensions) better than all other participants - the metric to judge being an "approximate median significance" of the subset of events that the user classifies as "signal". This is given by the formula
AMS = sqrt {2 * [(s+b+10) * log(1 + s/(b+10)) - s] }
where s and b are the number of selected signal and background events, respectively. By "selected" it is meant that they fall in the "acceptance region", i.e. that they are classified as signal by the algorithm chosen by the user.
If you look at the above formula you notice the presence of the "regularizing" term 10 accompanying the background entries: this is meant to prevent users from going for a very tight acceptance region, where background b goes to zero and even a very small amount of signal could make the score go very high. In this way the ATLAS designers of the challenge protect the score from being driven by statistical fluctuations in the users answers. In other words, the winning classification will be chosen in a way which does not depend too much on flukes.
There are so far 380 teams competing for the three prizes (of 7000,
4000, and 2000 dollars, respectively), and there are still over three
months to go... It will be a very interesting battle. It is interesting
to see that nobody is using the allowance of up to 5 submissions per day
- the top submitter is currently at second place, Triskelion, with 65
submissions in almost one month of competition.
Let us look at the current situation of the "leaderboard", which lists all the challengers and their best score among the classification attempts they so far submitted (up to 5 per day!). Mind you, these are approximate scores: they are computed using only 18% of the total answer, so the winner of the final challenge is not necessarily the one appearing on top.
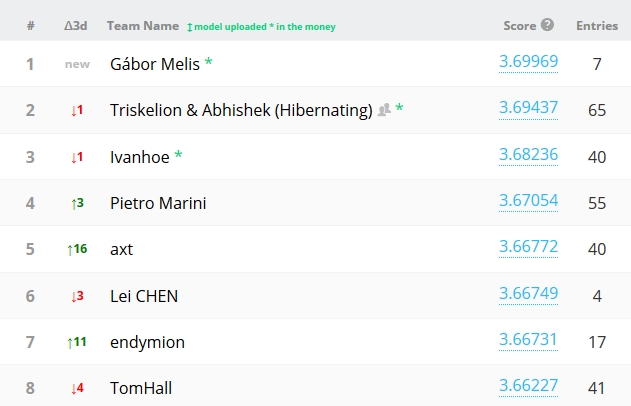
As you see, the top score is in the 3.7 "sigma" range - this means that such a classification would, on 2012 data, produce a 3.7 sigma excess of H->tau tau events, if systematics are neglected (at least that is what I understood). It is foreseen that the final winning trio will reach AMS values in the 4.0 - 4.05 range (but surprises are possible - and entertaining!).
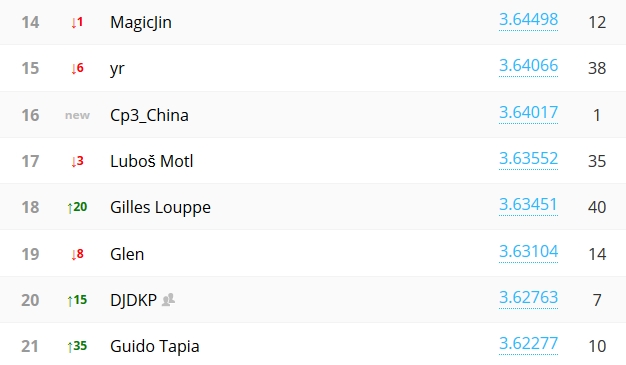
Scrolling down the list we find a known participant who is ranked in the top 5%: Lubos Motl. Is that somebody using his name or is it our real guy ? I bet it's Lubos indeed. He is a smart guy and technically versed, so I would expect him to be able to exploit the available technology to obtain a very good result, as the score shows. But of course, the real winners of the competition must show something more than just off-the-shelf software, however powerful.
And scrolling further down quite a bit we find my own submissions. Mind you, I have only submitted tests performed by running on small samples of training data, and with no intention of competing for a prize: I am testing an algorithm I myself designed, based on the idea of "nearest neighbors". Yeah, yeah - of course I'd love to win a prize; but I well know that it would take a LOT of effort.
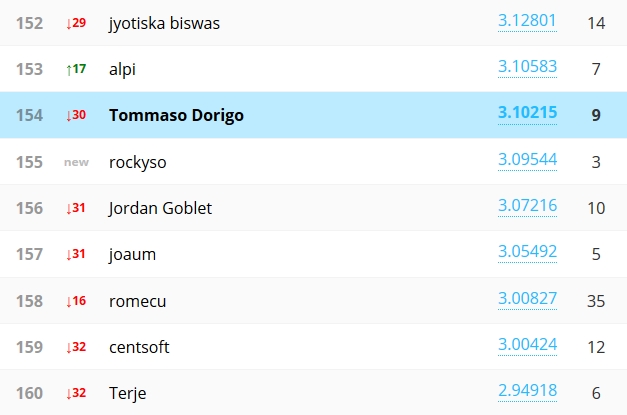
What I do want to do, by participating in this nice challenge, is to verify that by training my algorithm on all the data it will reach the 3.5-3.6 range of AMS which is the top notch for classifiers in this problem, and corresponds to ones which have applied the "boosting" technology - a rather complex topic which I may not discuss here today (but if you're curious you can look it up, e.g. in Wikipedia). However, my code is very slow, and I estimate that it will take of the order of one month of CPU to produce a reasonable result. Of course, I could break it into smaller chunks and run it in parallel on many different machines, collecting and reassembling the result at the end - but that is a bit too much work for my taste at present!
So that's it as of today - I must say that the ATLAS folks have done a great job of interesting the community on a very tough but intriguing problem. The challenge is not an idle one: the code used by the best submitters will be no doubt used by ATLAS in their future analyses.